
enjoy your stay
raw stream of consciousness about ml and random stuff. notes related to stuff that i do, read etc.
Note to self (2): MAKE SURE SAVING CHECKPOINTS WORKS UNLESS YOU WANT TO WASTE 3HRS OF A TRAINING RUN
Note to self:
NEVER INSTALL PYTORCH THROUGH CONDA UNLESS YOU WANT TO WASTE 2.5HRS OF YOUR LIFE
pip is the goat
UPDATE: PyTorch realized this too rofl
UPDATE 2: i am a uv fan now.
simply lovely
0128
essay ideas:
- "to transcend retardation, you must first embrace it"
- "why Before Sunrise is one of my favorite movies"
0101
hny; it turns out you can just write a simple ssg for your obsidian files in a <50 LoC build.py without using hugo or jekyll whatever haha
2025
1228
erm..this thing on...
there's a cognitive overhead to every tool that might be doing something with your input. keeping that boundary clear (where the AI lives, where it doesn't) is probably healthier for actually thinking through problems yourself versus reflexively outsourcing everything to a completion.
0625
trigger "yay you might get a job" workflow
0620
QoL improvement 1: bit the uv bullet
0619
life update: i am a discord mod now (half-joking)
0613
will's search agent has a pretty similar flavor to my wikigame env huh.
the "knowledge" vs "intelligence" debate for llms is the dichotomy between "can the model recall this fact?" to "can the model figure it out with tools, search, and reasoning?" which can only be decoupled in an ideal world.
we have recall benchmarks as well as agent benchmarks, but there is an evaluation gap in the middle. my initial research suggests there is no bench to study when a model should rely on it's internal knowledge vs when it should tools (and more importantly, use them effectively).
a reasonable proxy for this would to make llms play wikigame, i feel.
0507
<3
0505
GRPO has moved beyond language reasoning; if you have a verifiable task and a base VLM, you can show consistent gains on grounding, counting multimodal etc. While initial experiments/efforts are certainly interesting, there is a common theme about unfaithful traces, limited generalisation, and an obsession with "aha" moments. And a lot of blame is put on SFT...
I personally feel that throwing traditional tasks isn't necessarily the right direction to draw very strong conclusions, but again these are very early investigations and haven't been tested on scale. It's kind of obvious of that you don't want to overtrain small models, so it's still an open-ended question about what is the best recipe to upgrade small reasoning models. My hypothesis is that it depends on what your task is.
For instance, let's look at something VLMs are genuinely terrible at: Spatial Reasoning. Is this a fundamental limitation? Well, Google [@chenSpatialVLMEndowingVisionLanguage2024] says it's a data problem. You'll see significant capability improvements and emergent spatial reasoning if you pre-train on the right kind of data.
How do you synthesize such data:
- segment and label objects
- predict dense depth, and
- Lift 2d scene into a 3d point-cloud
- Based on the analysis on this lifted scene, you can compute all distances that you want
- And now you can use appropriate prompt templates, use numeric answers to generate conversation with a LLM
- Repurpose the conversation as a VQA example with artificial CoT
Now, Google didn't open-source anything related to this project, but I found a community-source implementation
Full disclosure, the author seems to be motivated about this exact problem and about 10 days ago, they released a model...but it seems they just SFT'd over a small thinking vlm. I would definitely compare the performance of their model with mine. Another key difference is that their model is trained to do quantitative estimations too, I didn't consider those for two reasons 1) simplicity and 2) Intuitively, anything quantitive might not generalize for a small model without any spatial supervision during pretraining. So I adapted the VQASynth pipeline to drop all numerical templates, skip metric scaling, and change the templates. Additionally, I also added more predicates like support/under, containment, relative sizes etc.
Now in order to endow a VLM with spatial reasoning (without pre-training) you have to resort to good old SFT. So, I generated about 10k samples with this approach and finetuned qwen. After that it's just RL, the reward design is extremely simple for these tasks as it is a sparse reward settings.
For evaluation I just used the 3D tasks for CV-bench (to save compute, I skipped 2D split for now and also I haven't yet done RL for object-counting). The current checkpoint has significantly improved on spatial reasoning (12pp). The base model is around 50% which might seem impressive but so is a coin-flip when you have only two options.
So that's progress so far, I do have to train my model for more longer (more steps), and conduct more extensive evaluation (note that i have also not evaluated the SFT only performance so idk how much boost RL gave)
0501
does knowledge distillation really work for reasoners the same way?
0430
would chess players appreciate that we fine-tune language models using an elo system?
think i just turned it the last homework of my life (unless i do a phd, seems unlikely now)
0429
two blog posts i am considering to write about:
- on knowledge vs intelligence
- SPCT for agentic search
0428
thunderkittens in a nutshell:

0427
all you need to reach agi is to lock up a bunch of autistic people in conference room and let them cook
--is what a friend said to me when i told him about a ML reading group
GRM paper notes:
REDACTED
0422
i guess i have figured it out now, how i am going document stuff
- ʕ•ᴥ•ʔ for longer posts (preferably more than 280 characters)
- keep updating small things about work, etc. here (as i used to)
- and x dot com, welp...
0306
[@bonettaVisionLanguageModels2024] not sure if this is relevant to what am i doing but this is pretty interesting, will look into later; pretty much requires me to understand PPO a little although i think i have the intuition for it...
0217
on a quest to be a shape rotator
i regret not taking cs747 seriously, somebody tell 2020 me RL will be a big thing in 5 years
0210
i low-key want to see how SigLIP2 ViT-So-400m + ModernBert does on ImageNet
gave a nice presentation on SigLIP for my class
ok who i am kidding it was a great presentation (Saining was impressed)
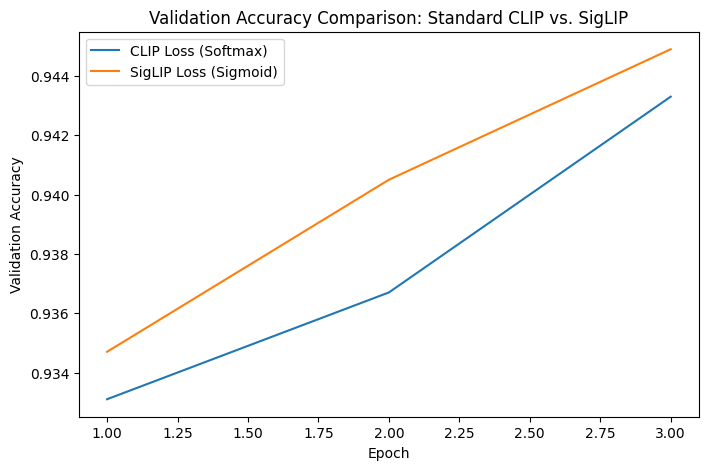
Stitched together a minimal CLIP-style DistilBert + ResNet18, trained it on CIFAR10 and guess what
Sigmoid loss still mogs softmax
0203
gemini api and pound cake both are disgusting
test leakage is all you need to go viral
i am not deriving FFT again
0130
what's the sweet size for model sizes, from the point of it being usable...
we have plenty of (open) models around a few billion, tens of billions and then, suddenly around half a trillion (405, 680)...
not too many in the couple of hundred billion mark (except dscoder2.5, maybe some qwen models)
ah i wish gpt3 was open-source
what if:
Sam comes to his senses and open-sources o3-mini, and hosts it for dirt cheap too (since they have an amazing infrastructure).
OpenAI just wins, then?
0129
a wise shrek once told me, "i don't believe in libraries"
never deleting this app
0122
new year, two months of sickness (physical and mental) we are so back
2024
1128
these are getting more and more infrequent.
only key takeaway from last 10 days is to use managed/unified memory with cuda kernels until you understand how memory works...
avoid cudaMemcpyAsync and cudaMemsetAsync for the time being...
1117
time surely flies when you are down with flu...
https://github.com/assafelovic/gpt-researcher
can use some automatic prompt optimization...
1102
not writing cursive with a fountain pen is chaotic evil.
1029
man, DSPy is awesome, at least now i feel as if i am not getting overpaid for just writing prompts.
1028
deconstructing a search engine, let's stick to a domain first (medical for e.g.)
- there are multiple medical databases (PubMed, SemanticScholar, etc...)
- each have a traditional search and their own api
- now you have "agent" that can crawl these databases, figure out how to query it
- and you need a model/workflow to transform a natural query to an api query.
- do you just tailor prompts for each database, kinda cring.
- what about automated prompt engineering, DSPy??
- search engines that leverage DSPy
1026
i got work do to but it's saturday night so

1024
training curve btw, should have used early stopping (figured it's just one epoch).
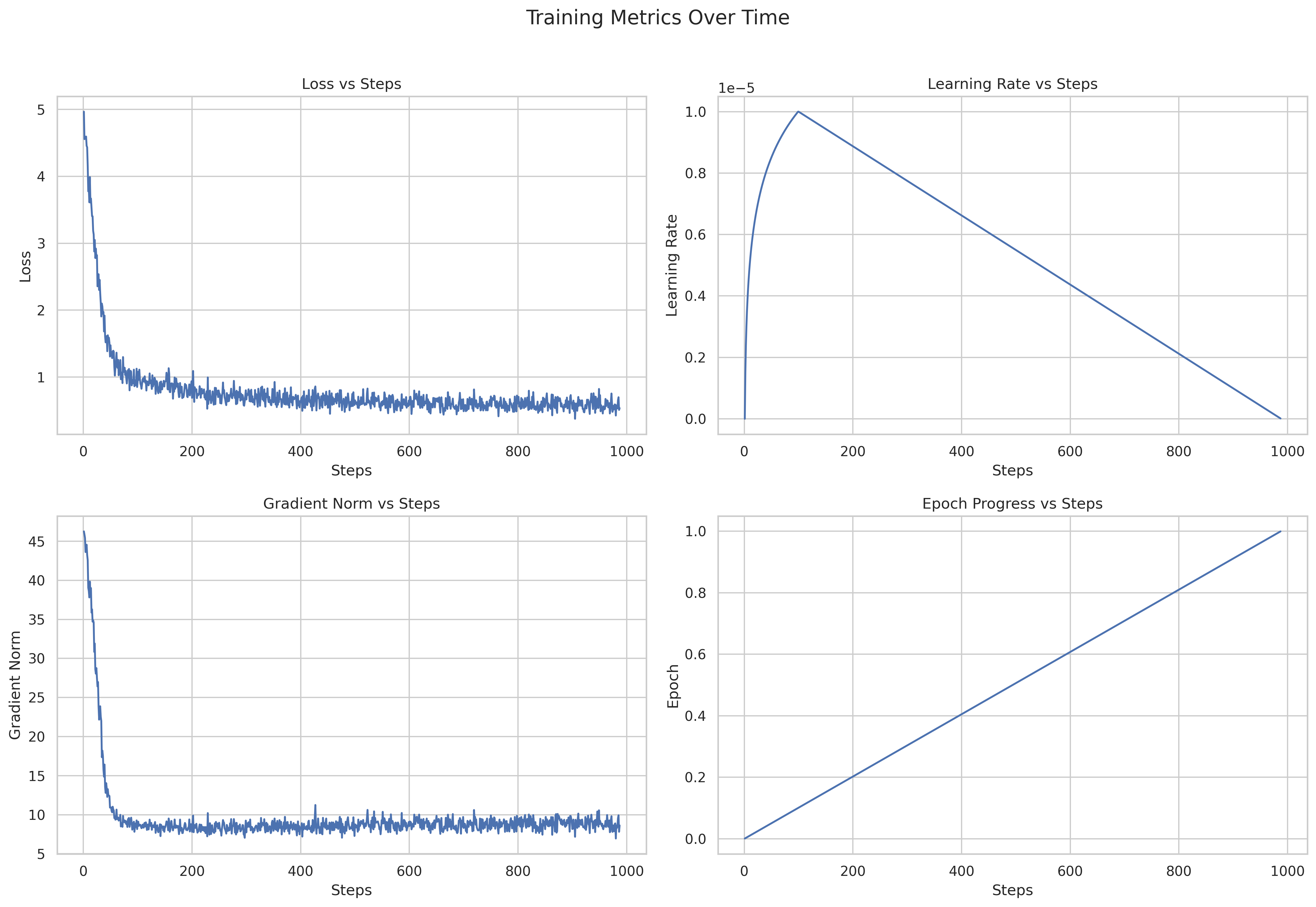
1023
ok i'll bite, it's rag for medical domain (the over-engineered gpt wrapper over a couple of sources) and i must research/experiment to make it better i suppose other priorities today:
- applying to openai residency, preceded by embellishing my cv
- i'll do the visa tomorrow
- working on cola and starting cuda stuff
switching gears to doing some query optimization/prompt engineering stuff; should line up well with the blog i've been trying to write for over a month
maybe if do end up learning somewhat about diffusion and vlms, might become capable enough to work at moondream.
1022
dse-qwen2-korean should be ready in about 19 hours...burning a 4xA100 for 30hrs lemao
log-scale normalization is better than clipping?
now we're doing feature-wise weighting before computing cosine similarity, which means features with higher variance in the training set will contribute more to the similarity calculation. it maintains the normalization benefits of cosine similarity while incorporating the feature importance weights
have to experiment with different normalization strategies for the feature weights: basic, softmax-based, min-max, log-scale.
also have to see how to see how (sighs) FID scores change.
1021
 i am trying
i am trying
so what am i working on right now, well, a bunch of things:
- at work i was extensively pushing to use multimodal rag based on colpali, and so we compromised for dse; finetuning should be straightforward, hoping it works out well
- all you need then is this encoder + claude.
now, onto more interesting things:
- learning CUDA by writing kernels for compositional linear algebra https://github.com/wilson-labs/cola
- improving the guided diffusion technique proposed in https://github.com/Agentic-Learning-AI-Lab/procreate-diffusion-public
this in itself is too much work on my plate but i also have teaching linear algebra and classes (obviously)
good luck me
1019
computers understand bits, llms understand vectors
i might actually cook with this blog...
all you need to learn diffusion is
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- https://yang-song.net/blog/2021/score/
estimated reading time for them combined is 78 mins
you can be an expert at diffusion in under 2 hours
that's less than 2 weeks btw
diffusion models are a journey that's equal parts math, magic, and machine learning.
1017
i always don't use version control but when i do i spam a bunch of Update README.md
1015
2 hours of sleep, on a sugar rush, and forcing myself through a lecture on approximate inference. i think i should just post that lmao.
next 72 hours are going to be brutal so i've been using vim
- i have to learn cuda
- i have to relearn vector calc so that i can attempt this horrifying assignment on bayesian linear regression
- have to train a 2b vlm
- proctor a couple of exams
and if time permits work on two research projects
am i too hopeful or thoroughly cooked
